
Double Clicking Python Pickle : Internal Working
Unveiling the Mysteries of Python's Pickle: How Does It Really Work?

Have you ever wondered what happens when you use pickle.dumps() ?What magical process converts your complex Python objects into byte streams? Under the hood, Python's Pickle module is significantly more than a simple tool; it functions as a virtual machine, executing a series of opcodes to serialise and deserialize objects. Let’s smooth down this mystery and dive into Pickle’s inner workings!
If you are new to Python's Pickle module or want a refresher on the fundamentals, check out our introductory guide: Basics of Python's Pickle: Serialization, Deserialization, and Protocols
The Pickle Virtual Machine: Where the Magic Happens
To understand the internals of Pickle fully, we need to drain up the Pickle Virtual Machine (PVM). PVM is at the core of how pickle handles serialisation and deserialization. It works by executing a set of low-level instructions called opcodes.
Stack Based Architecture: The Backbone of Pickle
The PVM operates on a stack, pushing and popping objects during both pickling (serialization) and un-pickling (deserialization). The PVM generates matching opcodes for each item it encounters, and these opcodes are subsequently utilised to produce the final byte stream.
Now that the significance of the stack in the PVM has been established, let's examine the specific commands: the opcodes, that instruct the PVM on how to function Understanding these opcodes provides insight into how each object type is serialized and deserialized.
Decoding Opcodes: The Building Blocks of Pickle
Opcodes are the low-level commands that tell the PVM exactly how to serialise or deserialize each object. Different Python data types have unique opcodes that guide their serialization. By using the pickletools module, we can see the opcodes that Pickle generates during serialization, providing a experience into how Pickle's virtual machine operates under the hood
import pickletools
import pickle
# Example dictionary
data = {'x': 12, 'y': [1, 2, 3]}
# Serialise the object
pickled_data = pickle.dumps(data)
# Deserializing the byte stream to see opcodes
pickletools.dis(pickled_data)See how the PVM encodes objects into opcodes with the output below:
0: \x80 PROTO 5 # protocol version
2: \x95 FRAME 0x000000000000004f # Marks a Frame
11: \x94 DICT # Start of a dict object
12: \x94 MARK # Mark stack for dict key-value pairs
13: \x8c SHORT_BINUNICODE 'x' # Push key 'x'
18: K BININT1 42 # Push value 42
25: ] EMPTY_LIST # Start a list object
33: e APPENDS # Append list to dict
35: . STOP # End of the streamImagine we are pickling an object that contains multiple references to the same object. If Pickle relies solely on a stack, it would have to serialise every occurrence of the same object repeatedly, which would be a time and memory consuming operation.
What the heck !! How to solve this problem in real ??
Memoization: How Pickle Remembers to Forget Redundancy
Memoization (memo) is Pickle’s way of eliminating redundant serialization. Imagine it as a Pickle keeping a 'notebook' where it notes down objects it has already seen. When it encounters the same object again, Pickle simply refers back to its 'notes' instead of re-serializing, which saves time and memory. Let us go through an example
import pickletools
import pickle
a = []
b = [a]
a.append(b)
pickled_data = pickle.dumps(a)
# Deserializing the byte stream to see opcodes
pickletools.dis(pickled_data)The PVM encounters
aand assigns it a memo.It encounters the reference to
binsidea, assignsba memo, and proceeds to serialise it.When the PVM encounters the reference to
ainsideb, instead of pushingaonto the stack again, it uses the memo from Step 1 to mark the reference.The cycle is broken, and serialization completes without recursion!
Now we will visualise it to get a clear view.
First Pass:
Object
a→ Serialize, memoize as0.Object
b→ Serialize, memoize as1.
Second Pass (Circular Reference):
Encounter
ainsideb→ Refer to memo0(avoiding redundant serialisation).
The output below will show you how the PVM applies the Stack and Memo to process objects efficiently.
0: \x80 PROTO 4 # protocol version
2: \x95 FRAME 9 # Marks a Frame
11: ] EMPTY_LIST # Create empty list
12: \x94 MEMOIZE (as 0) # Save Object as memo 0
13: ] EMPTY_LIST # Create empty list
14: \x94 MEMOIZE (as 1) # Save Object as memo 1
15: h BINGET 0 # Retrieve Object memo 0
17: a APPEND # Append Object
18: a APPEND # Append Object
19: . STOP # End of Serialization StreamWithout memoization, serializing objects with repeated references would lead to inefficiency, both in terms of time and memory. The stack alone would not be sufficient because pickle would treats each occurrence of an object as a separate entity. Memoization acts as a map or dictionary where Pickle records the objects it has serialized so it can reference them later, thus optimizing the serialization process.
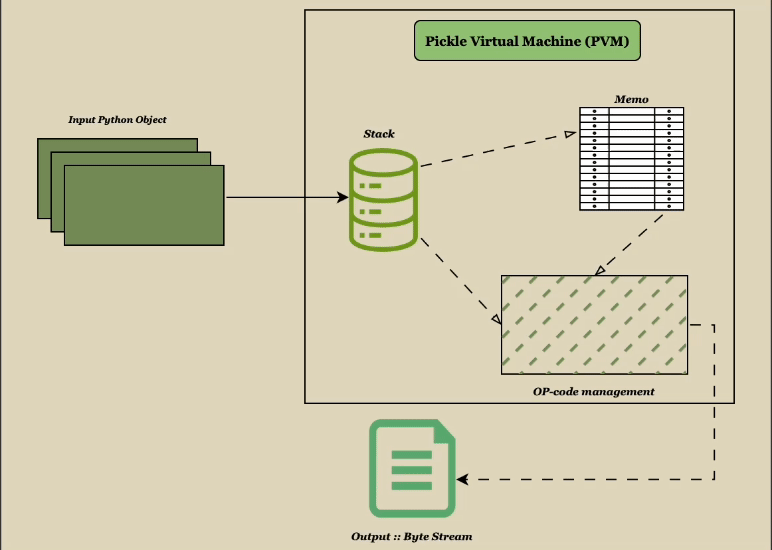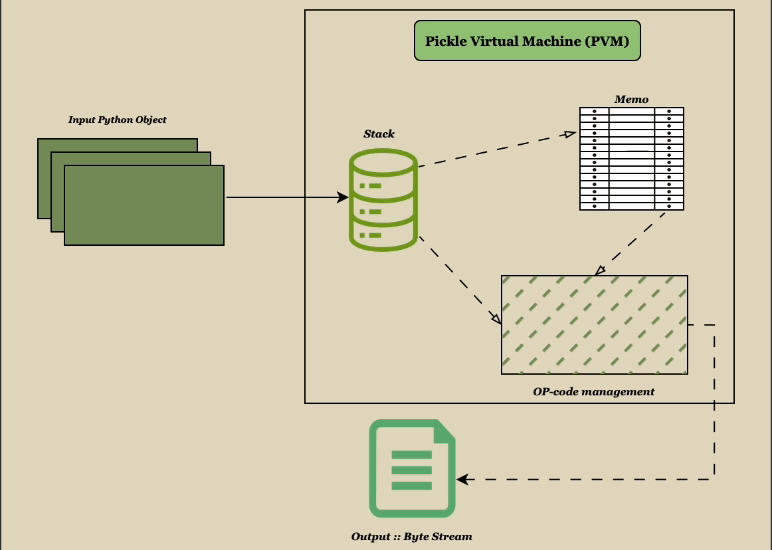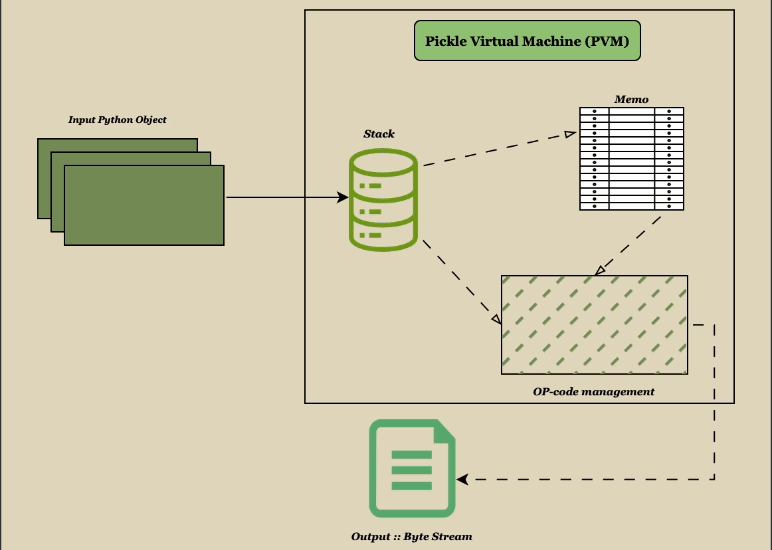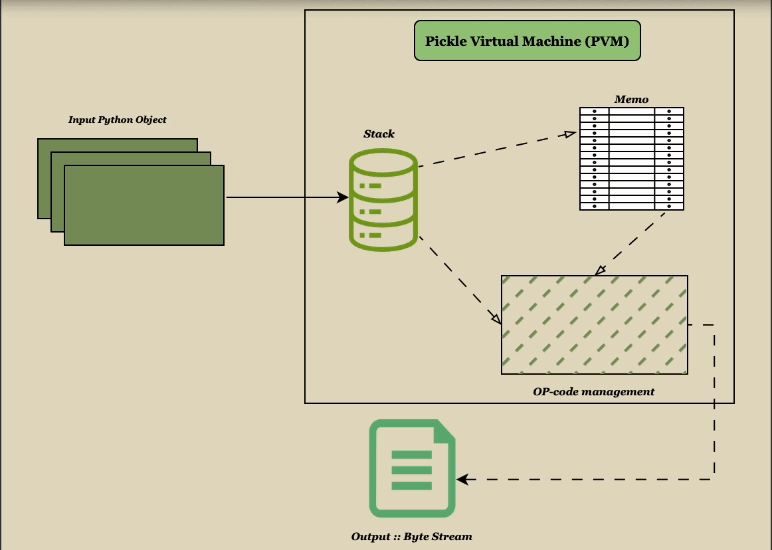
Spotlight on you
Have you encountered issues with redundant serialization or circular references in your work? Understanding how memoization works can help you debug such problems more effectively.
Memoization optimizes how Pickle handles repeated objects, but what about handling extremely large datasets? Knock !! Knock !! Frames in the house….
Pickle Frames: Breaking Big Data into Manageable Chunks
Pickle frames, introduced in Protocol 4, act like breaking a large Object into smaller chunks, making it easier to handle and process. Instead of serializing an entire large object at once, Pickle `frames` allow the data to be processed piece by piece, significantly boosting performance, especially when dealing with massive datasets and objects.
Why Frame matters:
Faster I/O: Handles large objects in chunks for quicker serialization.
Memory efficiency: Avoids loading entire objects into memory at once.
In short, frames are essential for handling large datasets and complex objects efficiently, making Pickle a powerful tool for data-heavy tasks like machine learning, etc,.
Wrapping Up: Key Takeaways on Pickle's Internals
Pickle leverages a stack-based architecture to manage object serialization, uses memoization to eliminate redundant data and handles large objects efficiently with frames. These mechanisms work together to enhance Pickle's speed and efficiency, making it a powerful tool for complex and large-scale data serialization tasks.
For those who want to dive deeper and see all the example codes from this blog, we’ve got them on GitHub. Feel free to explore and experiment!